大模型基础
大模型基础知识
只是一些杂碎的知识罢了
基础
- 现在的语言模型大多数都是自回归的语言模型,通过链式法则表示:$$p(x_{1:L}) = p(x_1) p(x_2 \mid x_1) p(x_3 \mid x_1, x_2) \cdots p(x_L \mid x_{1:L-1}) = \prod_{i=1}^L p(x_i \mid x_{1:i-1}).$$
- 温度参数用于控制生成的随机性,越高随机性越高: $$\begin{aligned}\text { for } i & =1, \ldots, L: \x_i & \sim p\left(x_i \mid x_{1: i-1}\right)^{1 / T},\end{aligned}$$。从公式中可以看出来,温度越高,不同token的概率会更加接近
- 信息熵和交叉熵:$$H(p, q)=-\sum_x p(x) \log q(x)$$
分词和词向量
- 难点主要集中在分词标准,切分歧义和未登录词三部分
- 尤其是对于中文,上述问题更加严重。可以使用jieba工具实现中文分词。当然,现在一般不需要在这个地方进行改进
- 分词的方法现在主要有字典匹配、机器学习方法。字典匹配主要是一个贪心或者是图的过程。而机器学习方法现在用的比较多,根据在句子中的位置进行标记,包括 HMM,隐马尔科夫模型/CRF,条件随机场/深度学习。其中jieba对于未登记词的统计就是通过HMM实现的。
- 关于分词的详细之后再说吧
- 现在用的是embedding。以前用的是one-hot或者是word2vec,根据统计学原理,有CBOW和skip-gram两种算法,前者是上下文预测中心词,后者反过来。基于词之间相近性来构建相似度关系。不如embedding训练。
另一些基础
- 三大特征提取器:CNN、RNN、TF
- RNN循环从前往后获取信息,但是优化太难了而且不能并行。后面出现了LSTM和GRU,但是性能还是太弱了。不过现在使用TF依然有借鉴RNN的地方
- CNN和图片中的原理一致,利用相关关系来卷积提取特征,可以并行并保留相对位置但是问题是定长
- Transformer也定长,而且并行计算有一定压力,但是无奈性能强。
一些关于架构的面试题(或者说NLP面试题)
- BERT架构。google的好东西,用的双向Transformer架构实现。有很多科技:(1)双向Transformer(2)Masked LM 有一些单词被mask,之后可能被mask或者random或者不变。从而实现对应任务/放置过拟合/使得训练方向恢复一点。(3)NSP任务,做了下一个句子预测任务,取两个句子来判断是不是下一句。实际上BERT做分类任务都可以。
- 为什么LLM是Decoder架构。对于语言模型其实可以分为Decoder/Encoder only和两者混合的模型。不同的任务不同。首先,Encoder是Masked LM对生成任务没啥用,泛化性不太行。此外,双向Encoder会有低秩问题会削弱模型表达能力。而Encoder-Decoder由于参数量多一点,性能好一点。此外就是可以复用KV-Cache,而encoder-decoder的PrefixLM做不到。
- google对比了5B情况下各种架构的性能。decoder-only zero-shot性能最好,encoder-decoder需要做一定的finetune。
激活函数
- 可太多了,主要有三类变体:ReLU、sigmoid、新东西。激活函数的设计核心在于:
- 在输入
x满足某些条件时,为恒等映射; - 在输入
x满足另外一些条件时,为置零映射; - 在输入
x是一个较大的正值时,更希望为恒等映射;在输入x为一个较小的负值时,更希望是一个置零映射;
- 在输入
- ReLU好理解的,变体有Leaky ReLU和PReLU(加了参数),ELU,GELU(虽然满足了所有条件但是计算比较复杂因此需要近似计算),Swish
- sigmoid、tanh两者可以转换
- SwiGLU利用门控线性单元函数做激活函数,向量做了门控之后和sigmoid做向量点乘。
llm概念
-
现在的模型主要分为GPT、Bert、XLNet、RoBERTa(更多的训练,更强的稳定性)、T5
-
PrefixLM和Casual LM的区别在于,后者的Encoder-Decoder架构中是共享Transfomerm架构但是通过mask实现的,而前者则是对立的参数
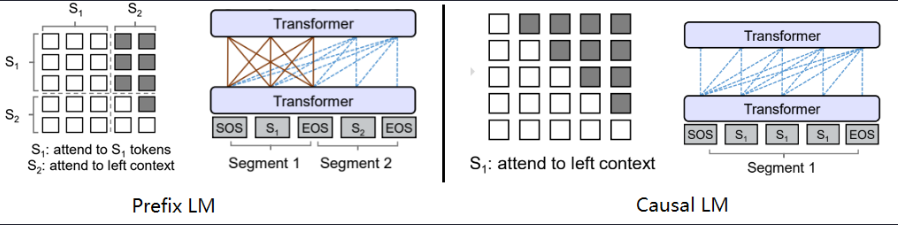
大语言模型架构
现代的还是Attention居多
Attention
$$Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$$
- self-attention是自身序列位置之间的关系建模。target-attention则是和一组相关序列的关系建模。
- 常规attention中的k=v,self-attention的实现同样可以选择是否相同
- 主流的attention主要有
- Scaled Dot-Product Attention 最常用的Attention机制
- Multi-Head Attention: 这是Transformer中的一个改进,通过同时使用多组独立的注意力头(多个QKV三元组),并在输出时将它们拼接在一起,但是在设计上没啥区别
- self-attention计算中的padding mask,对于mask需要设置值为**-inf**使得softmax之后输出为0
Transformer
- Transformer中使用的是多头注意力机制,并行的学习多个不同的特征(实际上没有多并行),但是还是得降维放置计算量过大。
- Transformer通过使用点积并缩放放置梯度爆炸。由于完成qk计算之后是进行一个softmax的$e^{qk}$操作,如果不做缩放的话会到一个很大的范围,且由于在正区间的指数提升,很容易成为one-hot,导致梯度消失。解决方法就是缩放使得方差变为1。
- BERT使用的是gelu和self-attention
- BERT如何处理长文本:1、截断或者填充 2、sliding windows,通过将长文本分为多个短文本最后汇合 3、利用分层模型处理 4、使用针对长文本的模型。
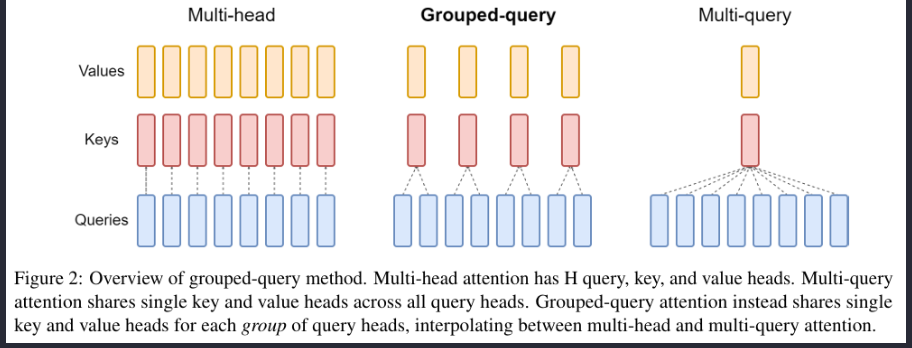
MHA & MQA & MGA
-
MHA $$MultiHead(Q,K,V)=Concat(head_1,…,head_h)W^O \ where ~ head_i = Attention(QW_i^Q, KW_i^K, VW_i^V) $$
-
MQA 所有头共享一份key和value而单独使用不同的Query
-
GQA 折中方案,分组采用query分为N组,每个组共享一个Key和Value
Flash Attention
原理很简单,尽可能使用SRAM来存储,减少通讯从而大大减少Attention计算时间,其中涉及到了很多的kernel fuse操作。
Flash Attention的计算有点基于稳定的Softmax,通过拆分计算方程去除依赖来实现并行化(对应的会提升计算代价)

从简单来看的话原理也简单,通过对矩阵分块计算,每个块都可以完全加载到SRAM上,并通过for循环实现整个注意力的计算。
其他细节
Transformer计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
- K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。
- 为了计算更快。矩阵加法在加法这一块的计算量确实简单,但是作为一个整体计算attention的时候相当于一个隐层,整体计算量和点积相似。在效果上来说,从实验分析,两者的效果和dk相关,dk越大,加法的效果越显著。
为什么在进行softmax之前需要对attention进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
- 这取决于softmax函数的特性,如果softmax内计算的数数量级太大,会输出近似one-hot编码的形式,导致梯度消失的问题,所以需要scale
- 那么至于为什么需要用维度开根号,假设向量q,k满足各分量独立同分布,均值为0,方差为1,那么qk点积均值为0,方差为dk,从统计学计算,若果让qk点积的方差控制在1,需要将其除以dk的平方根,是的softmax更加平滑
为什么在进行多头注意力的时候需要对每个head进行降维?(可以参考上面一个问题)
- 将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息
- 基本结构:Embedding + Position Embedding,Self-Attention,Add + LN,FN,Add + LN
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
- embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
简单介绍一下Transformer的位置编码?有什么意义和优缺点?
- 因为self-attention是位置无关的,无论句子的顺序是什么样的,通过self-attention计算的token的hidden embedding都是一样的,这显然不符合人类的思维。因此要有一个办法能够在模型中表达出一个token的位置信息,transformer使用了固定的positional encoding来表示token在句子中的绝对位置信息。
你还了解哪些关于位置编码的技术,各自的优缺点是什么?(参考上一题)
- 相对位置编码(RPE)1.在计算attention score和weighted value时各加入一个可训练的表示相对位置的参数。2.在生成多头注意力时,把对key来说将绝对位置转换为相对query的位置3.复数域函数,已知一个词在某个位置的词向量表示,可以计算出它在任何位置的词向量表示。前两个方法是词向量+位置编码,属于亡羊补牢,复数域是生成词向量的时候即生成对应的位置信息。
为什么transformer块使用LayerNorm而不是BatchNorm?LayerNorm 在Transformer的位置是哪里?
- LN:针对每个样本序列进行Norm,没有样本间的依赖。对一个序列的不同特征维度进行Norm
- CV使用BN是认为channel维度的信息对cv方面有重要意义,如果对channel维度也归一化会造成不同通道信息一定的损失。而同理nlp领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
简答讲一下BatchNorm技术,以及它的优缺点。
- 优点:
- 第一个就是可以解决内部协变量偏移,简单来说训练过程中,各层分布不同,增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使损失平面更加的平滑,从而加快的收敛速度。
- 第二个优点就是缓解了梯度饱和问题(如果使用sigmoid激活函数的话),加快收敛。
- 缺点:
- 第一个,batch_size较小的时候,效果差。这一点很容易理解。BN的过程,使用 整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
- 第二个缺点就是 BN 在RNN中效果比较差。
简单描述一下Transformer中的前馈神经网络?使用了什么激活函数?相关优缺点?
- ReLU
$$ FFN(x)=max(0,~ xW_1+b_1)W_2+b_2 $$
Encoder端和Decoder端是如何进行交互的?(在这里可以问一下关于seq2seq的attention知识)
- Cross Self-Attention,Decoder提供Q,Encoder提供K,V
Decoder阶段的多头自注意力和encoder的多头自注意力有什么区别?(为什么需要decoder自注意力需要进行 sequence mask)
- 让输入序列只看到过去的信息,不能让他看到未来的信息
Transformer的并行化提现在哪个地方?Decoder端可以做并行化吗?
- Encoder侧:模块之间是串行的,一个模块计算的结果做为下一个模块的输入,互相之前有依赖关系。从每个模块的角度来说,注意力层和前馈神经层这两个子模块单独来看都是可以并行的,不同单词之间是没有依赖关系的。
- Decode引入sequence mask就是为了并行化训练,Decoder推理过程没有并行,只能一个一个的解码,很类似于RNN,这个时刻的输入依赖于上一个时刻的输出。
简单描述一下wordpiece model 和 byte pair encoding,有实际应用过吗?
- 传统词表示方法无法很好的处理未知或罕见的词汇(OOV问题),传统词tokenization方法不利于模型学习词缀之间的关系”
- BPE(字节对编码)或二元编码是一种简单的数据压缩形式,其中最常见的一对连续字节数据被替换为该数据中不存在的字节。后期使用时需要一个替换表来重建原始数据。
- 优点:可以有效地平衡词汇表大小和步数(编码句子所需的token次数)。
- 缺点:基于贪婪和确定的符号替换,不能提供带概率的多个分片结果。
Transformer训练的时候学习率是如何设定的?Dropout是如何设定的,位置在哪里?Dropout 在测试的需要有什么需要注意的吗?
- 一般用的Adamw,并设置lr_schedularDropout测试的时候记得对输入整体呈上dropout的比率
MoE
已经炉火纯青了,主要用于在提高性能利用。一个问题在于如何防止过拟合(采用Top-k或者加一些噪声)
MoE 通常是加在FFN层的,通过实现负载均衡来在较低显存占用的同时取得更好的效果
$$Importance (X)=\sum_{x \in X} G(x)$$
$$L_{\text {importance }}(X)=w_{\text {importance }} \cdot C V(\text { Importance }(X))^{2}$$
对门控电路的结果平方作为重要性,
但是在这种情况下的MoE的门控电路是不可微的,一种合理的方式是添加一个softmax之后近似,此时计算如下:
$$l_{aux} = \frac{1}{E}\sum_{e=1}^E(\frac{c_e}{S})*m_e$$
由于deepseek比较火,因此也需要着重强调一下deepseek采用的MoE架构。与其他的MoE不同的是,DeepSeek有一个共享的专家,且采用了更加细粒度的路由机制:
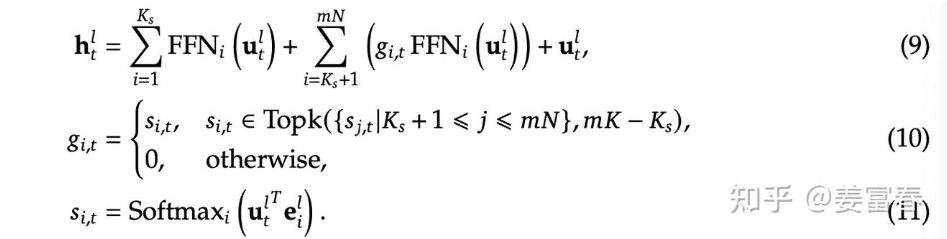
看图倒是很好理解,由$K_s$个共享专家、$mN-K_s$个专家和一个残差组成。对应的loss也有变动:

关于这个的计算核心,其实在前面要除的系数$K^`$,这个表示去除共享专家之后的专家数量,通过这个计算可以使得最终的负载和专家数量无关,从而算是减少了超参数的数量,只需要调整$\alpha_1$就好了。
此外,在实际推理或者训练的过程中,相较于模型的负载均衡,另一个需要考虑的问题是设备的负载,这个倒是比较好解决,论文采用了一个损失函数来解决:
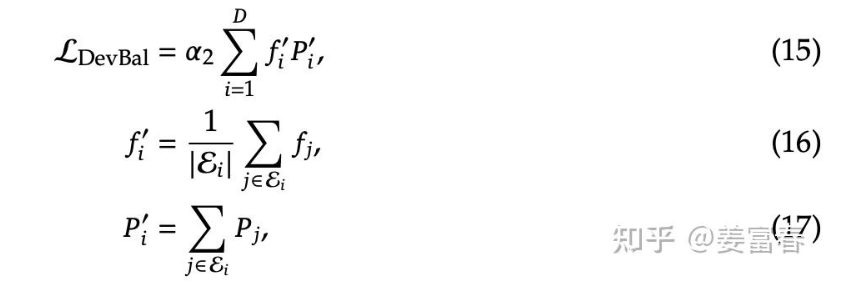
上述的改进只是V1的创新,实际上在此之后的V2,DeepSeek也做了创新:
- 首先筛选M个设备,之后从M个设备选择TopK个专家。
- 对通讯负载设计了损失函数
- 对于超出设备容量的Token,只采用残差的结果,当然在训练的时候也使用了10%的样本不做token丢弃
V3也做了改进,将softmax换成了sigmoid,可能是由于V3的模型尺度增大(专家数量增多),使用softmax的归一会导致TopK的数量不足,更倾向于一个平均值,而sigmoid则是在[0,1]范围内,避免了问题。
最后展示一下大图

Normalization
常见的归一化方案有LN, BN。
BN用来处理一批数据间的均值和方差
BN的作用:
- 允许较大的学习率;
- 减弱对初始化的强依赖性
- 保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础;
- 有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
BN存在的问题:
- 每次是在一个batch上计算均值、方差,如果batch size太小,则计算的均值、方差不足以代表整个数据分布。
- batch size太大: 会超过内存容量;需要跑更多的epoch,导致总训练时间变长;会直接固定梯度下降的方向,导致很难更新。
LN对于单个样本的特征进行归一化操作,限制很少,但是性能在CNN上不如BN。
还有一个Norm叫做RMS,仅仅就是减去了均值的部分
位置编码
Attention直接一个QKV就把位置信息搞没了,所以一般的做法两种:
- 输入的时候搞一下位置信息(绝对位置编码)
- 在Attention架构中加一下使得分辨不同位置的token
绝对位置编码:
- 训练式:直接将位置编码作为训练参数,但是问题在于外推性和固定的长度
- 三角式(Attention is all you need 中的应用):$$\left{\begin{array}{l}\boldsymbol{p}{k, 2 i}=\sin \left(k / 10000^{2 i / d}\right) \ \boldsymbol{p}{k, 2 i+1}=\cos \left(k / 10000^{2 i / d}\right)\end{array}\right.$$
相对位置编码(在Attention的时候计算相对的位置距离,考虑到的是NLP对相对位置更关注,具有外推性,对长文本处理能力更强):
- 经典式:相较于根据坐标实现注意力,其实现如下

把第一项中的位置编码去除,把第二项的位置编码换做二元位置向量。同理对于output也做相同的各操作。因而从坐标的位置关系变为一维的相对位置关系(之后的XLNET、T5、DeBERTa做了类似但改进)
特殊位置编码
- CNN式(乐)
- 复数式(少见)
- RoPE旋转位置编码(Llama在用)
RoPE
RoPE是苏神提出的相对位置编码。
二维下的计算:
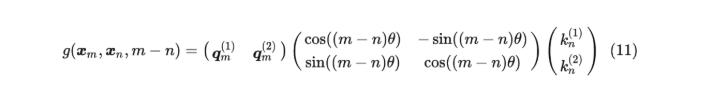
对于m,n的元素进行旋转。对于多维的,计算如下:
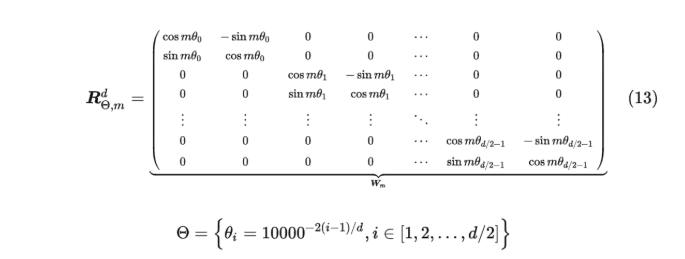
但是上述太稀疏了,所以可以直接展开:
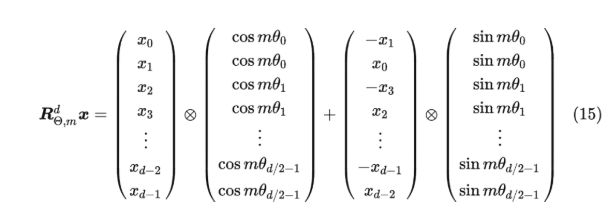
而且有一定的远程衰减性
token数量和模型参数量的关系
LN,BN,RMSnorm
LN对每个样本做norm,BN对于每个batch的对应特征做norm。从效果和任务来看的话,LN更贴近LM任务,而BN贴近CV任务。而今年来更倾向于使用RMSNorm,核心在于计算复杂度更低的同时性能并不差。
为什么post-Norm优于pre-Norm
一个简单直观的地方在于:
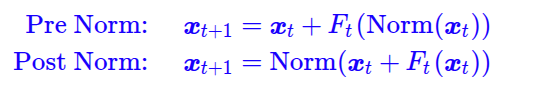
prenorm倾向于恒等分支而使得prenrom退化为一个宽而且浅的模型
Llama
Llama2用了如下技术:
- 绝对位置编码提供输入的位置信息
- 使用RMSNorm而不是LayerNorm
- QK使用RoPE相对位置编码
- KV cache使用能够GQA
- FFN采用的SiLU激活函数
Llama3相较于Llama2使用了SwiGLU,提高了数据的质量
并行化
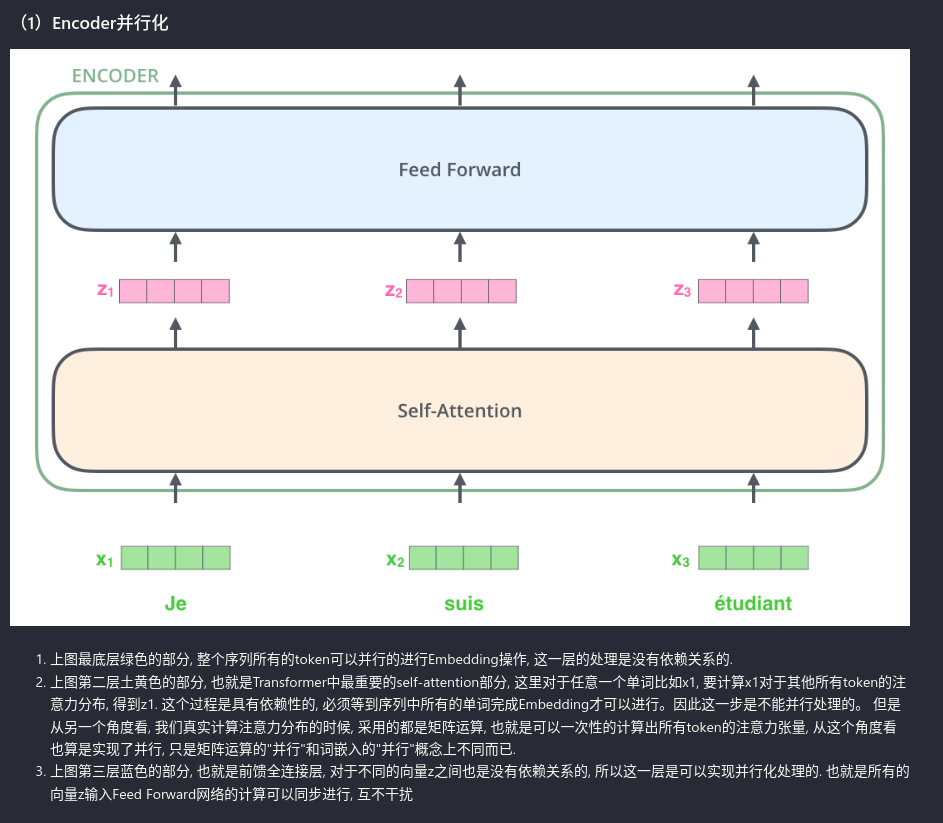
之前看过一篇系统并行化Transformer的论文,与这个问题类似,关键在于下一个操作对于上一个操作的维度依赖。比如token embedding是逐token操作,因此可以并行。才外上图的attention架构不能继续并行,对于MHA,还可以进一步实现并行化。最后的FFN是对每个token进行的,因此同样是可以实现同步进行的
DeepSeekv3
毕竟算是爆火的开源模型,应该是后续的一个重点。
创新点:
- DeepSeekMoE:通过引入偏置项动态调整专家负载,避免了传统辅助损失带来的性能损失。
- 多Token预测(MTP):在每个位置预测多个未来的 token,增加训练信号,提高模型的数据效率。
- FP8训练
- 基于DualPipe算法训练
- 还有一些结构上的创新:包括MLA,MoE等等
由于后续大概率不太可能参与模型训练的工作,因此还是得好好理解一下DeepSeek模型结构所带来的优势。
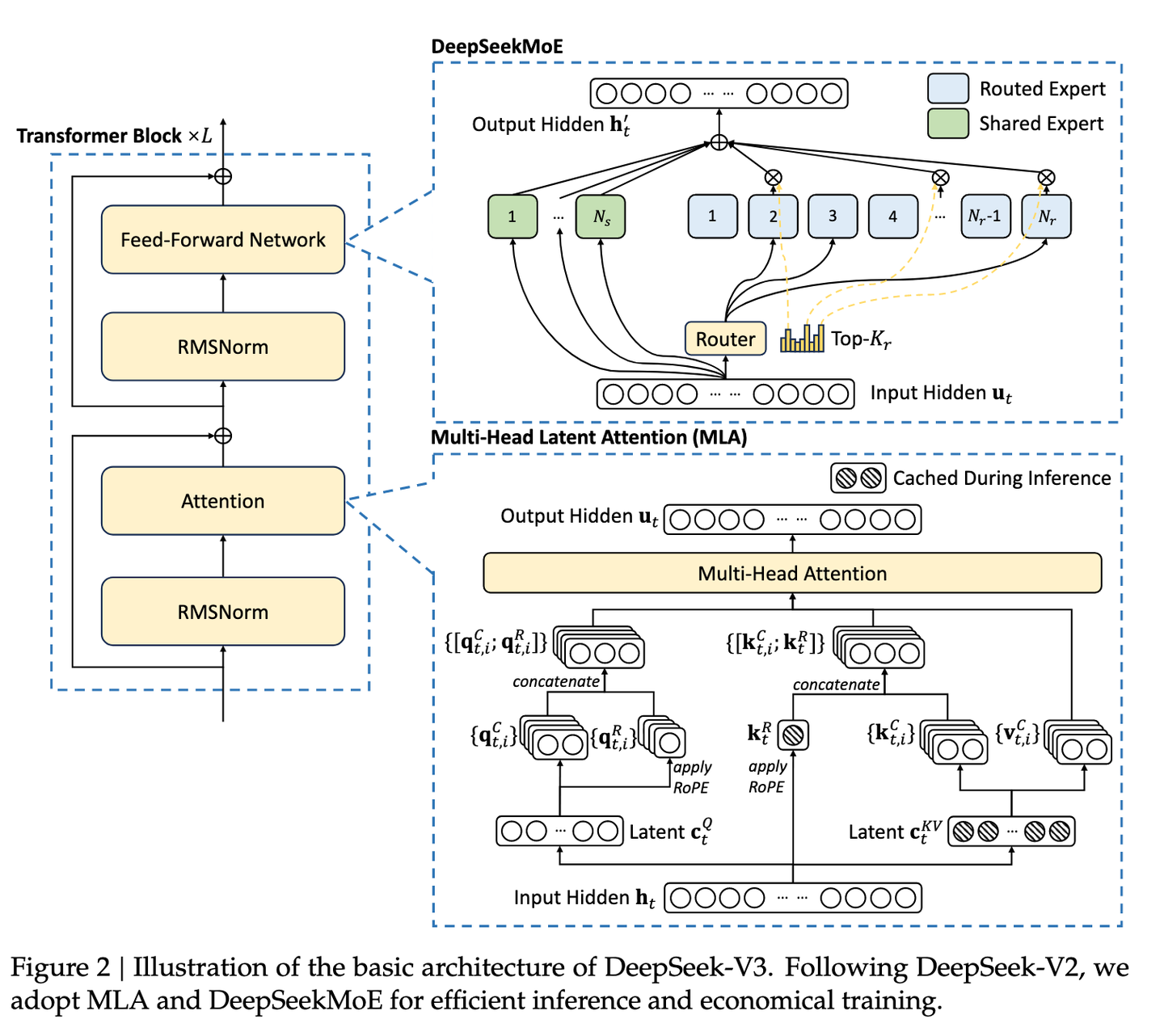
现在一般来说更倾向于搞稀疏MoE来实现更好的效果,但是问题在于稀疏MoE还需要用一些辅助损失来保证负载均衡/训练稳定。DeepSeek的MoE并没有采用辅助损失函数,而是利用偏置项实现。 在训练过程中,如果一个专家被过度使用,则减小其偏置项;如果一个专家被闲置,则增大其偏置项。这样,可以动态调整专家负载,使其达到均衡。
接下来是MLA(Multi-Head Latent Attention ),通常来说现在的Attention都是会用到KV-cache的,但是长文本+大batch直接给你内存整炸也不太好,因此一个可行的方案就是论文的MLA:
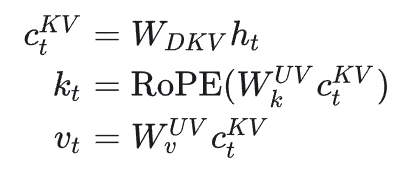
对于KV而言,采用一个降维矩阵得到降维后的特征C,之后再进行K V计算从而减少了显存占用。
还有一些可以提到的技术: Multi-Token Prediction (MTP)。一般来说训练可能倾向于进行下一个token的预测,论文这里引入多个预测模块来实现未来的输出,并计算损失,带来的好处就是:
- 增加训练信号: 通过预测多个 token,模型可以获得更密集的训练信号,提高数据效率。
- 增强预规划能力: MTP 可以帮助模型更好地预先规划未来 token 的表示,使其更好地捕捉长距离依赖关系,从而提高模型的性能
资源问题
- 数据并行:每个设备放一个模型
- 模型并行:模型拆分到各个设备上之后数据流动
- 张量并行:一个操作内并行计算
- 流水向并行:不同层之间并行计算
优化器并行,优化器(尤其是Adam),要占用2倍的模型参数量。
MoE并行
显存占用
一般模型参数半精度就是16bit,乘以2就是模型参数占用,但是训练时候还需要优化器,所以实际上需要6倍于模型参数的显存占用。
微调
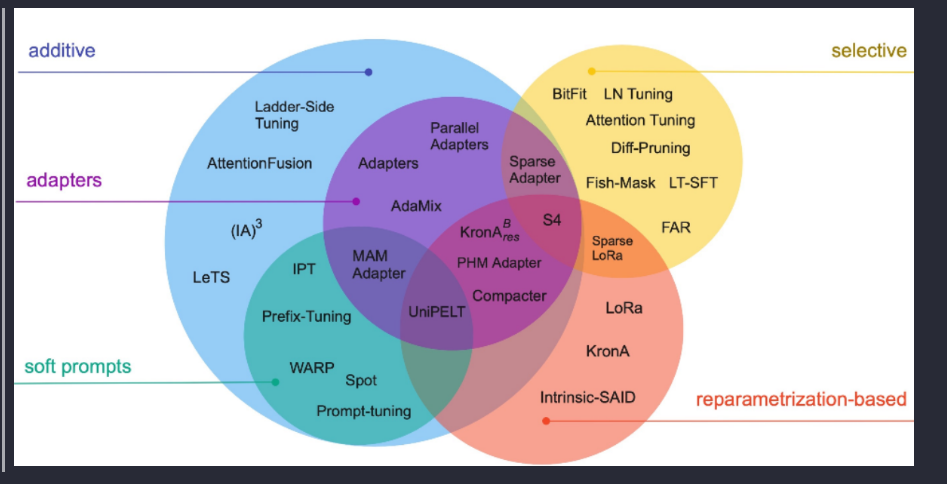
整体来说内容很多很多,比如基于模型参数的微调(A),选取部分模型参数更新(S)、重参数化(R)
PaLM: Scaling Language Modeling with Pathways
虽然论文只是搞出来了一个PaLM大模型,但是由于其提供了非常详细的profile信息,因此对预训练LLM有着极大的参考价值。
最大的PaLM 540B是在6000多个TPU上训练完成的,token数量高达780B。论文核心主要有以下几个部分:
- Efficient scaling,Continued improvements from scaling, Breakthrough capabilities, Discontinuous improvements, Multilingual understanding,Bias and toxicity
模型结构
模型结构倒不是很复杂,主要有如下技术:
- SwiGLU激活函数,并行化LayerNorm, MQA,ROPE,输入输出共享embedding,没有Bias参数,使用Sentence Piece词汇表


论文有如下论断:
硬件 FLOPs 利用率有几个问题。 首先,执行的硬件 FLOPs 数量取决于系统和实现,编译器中的设计选择会导致不同的操作数。 非物质化(Rematerialization)是一种广泛使用的内存使用与计算权衡技术。 为了使用梯度下降法高效计算大多数神经网络架构的后向传递,必须在内存中存储批次的许多中间激活。 如果无法全部存储,则可以重新计算某些前向传递操作(使某些激活状态重新实体化,而不是存储)。 这就需要权衡利弊,使用额外的硬件 FLOPs 可以节省内存,但训练系统的最终目标是实现每秒令牌的高吞吐量(从而缩短训练时间),而不是使用尽可能多的硬件 FLOPs。 其次,测量观测到的硬件 FLOPs 取决于计算或跟踪它们的方法。 观测到的硬件 FLOPs 是根据分析核算(Narayanan 等人,2021b)以及使用硬件性能计数器(Xu 等人,2021)报告的。
初始化
- 权重初始化基于 $W \backsim N(0, 1/\sqrt{n_d})$, embedding初始化基于 $W\backsim N(0, 1)$,此外还有layerNorm初始化为$W\backsim N(0, \sqrt{n}$。代码实现参考:
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
# in model
self.apply(self._init_weights)
- 优化器采用Adam(这里涉及到了权重缩放和优化器学习率缩放的问题,Adam会根据权重矩阵的均方根实现学习率的缩放,由于初始化的操作,使得不同module(embdding和linear)实现不同的缩放)。学习率的超参数采用的是:
| 参数 | 学习率(前10000step) | lr decay | $\beta1$ | $\beta2$ | global grad norm clip | weight decay | |
|---|---|---|---|---|---|---|---|
| 数值 | $10^{-2}$ | $1/\sqrt{k}$(k为步数) | $0.9$ | $1-k^{-0.8}$ | 均值$1$ | $lr^{2.0}$ |
- 损失函数。损失函数采用的语言模型损失(交叉熵而且没有采用label smooth),并加入了一些辅助损失保证训练稳定性:
if targets is not None: # target.shape = (B, S)
logits = self.output(h) # targe.shape = (B, S, vocab_size)
a = logits.view(-1, self.size(-1)) # a.shape = (B * S, vocab_size)
b = targets.view(-1) # shape = (B * S)
loss = F.cross_entropy(a, b)
if loss_mask is not None:
lm = loss_mask.view(-1)
loss = torch.sum(loss * lm) / lm.sum()
self.last_loss = loss
else:
# inference-time mini-optimization: only forward the lm_head on the very last position
if self.config.is_causal:
logits = self.output(h[:, [-1], :])
else:
logits = self.output(h)
self.last_loss = None
return logits, self.last_loss
注意,这里没有提到辅助损失函数,PaLM中使用的如下:$L = CE + z_{loss}$其中$Z_{loss}=10^{-4}\cdot log^2Z$简而言之就是让softmax的值更加接近于0。
- Seq Length: 2048 (可恶,好大)
- Batch Size: 前5000步512,11500步1025,25500步2048
- 位重现:保证随机种子+保证位重现从而能够完美复现
- dropout为0
- 奇怪的峰值状态,训练初期会出现忽高忽低的尖峰情况,但是进行了消融实验确定了并不是由于坏数据导致的,可能只是由于参数和数据恰好结合的结果
评估结果(不看了)
微调
其实也算是评估里面的内容,论文在SuperGLUE对PaLM进行微调,其中使用Adam $5\times 10^{-5}$学习率32Batch,在15000step就收敛了。
接下来是另一些重点,关于如何对token、参数等找到合理的参数和对应关系
模型记忆
模型的记忆能力
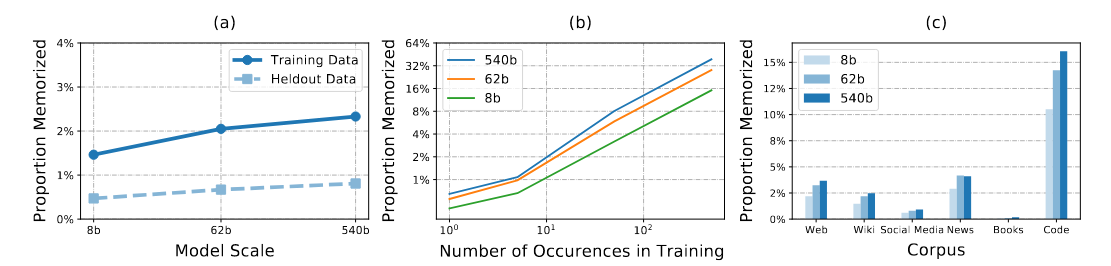
参数量和记忆能力是息息相关的,而且其中Code数据集的重复度相对来说较多,至于重复出现的频率同样也是参数量越大频率越高。简而言之:模型会对常见的模板产生完全匹配的连续性从而产生“记忆”。根据LM的原理来看,还是和数据相关的
上述问题顺带着会引出一些安全问题,当然整体来说不是本文的探讨内容,还是越多越重复的数据就会导致记忆性。
数据集污染(不看)
表现误差分析(不看)
关于Scaling的讨论
如何提高模型的性能,实际上只有四部分:
- 深度和宽度、token数量、token质量、不增加计算量的前提下增加模型容量(稀疏模型)
但是显然的,由于LLM训练的令人发指的计算量,对上面的部分进行详细的profile和性能比较对于一个企业而言是不可能的(还是得看各式各样的论文。)
上述是正文的内容,之后还有一些比较重要的部分。
计算占用
对于参数量为$N$的纯decoder架构,其计算量为$6N$,其中$2N$用于前向传播,$4N$用于反向传播。每个矩阵乘法需要依次乘法和一次加法。而密集注意力中的矩阵乘法为$6LH(2QT)$,其中 L、H、Q 和 T 分别是层数、头数、头维度和序列长度。加入知道吞吐P,那么峰值比例
$$R=\frac{P}{(6N+12LHQT)}$$
另外要讨论的是PerToken的计算量,对于不同的尺寸的参数有不同的结果:

这里详细计算还得确定一下。
重复计算的token
- 为什么要考虑在重复的数据集上做多次训练?Token危机。多个epoch训练实际上是会降低模型性能的!然而由于目前互联网上的token质量和token数量有限,如何实现较好的效果也是一个问题。
- 预训练数据集重复的影响是什么?过拟合
- 1、模型参数规模与tokens数量需要匹配 前面讨论了
- 2、多轮epoch的训练会降低模型性能 相较于大token少epoch训练,少token大epoch会导致过拟合
- 3、更大规模的数据集会缓解重复epochs对模型性能下降的影响
- 4、提高数据集的质量也无法挽救重复训练带来的过拟合
- 5、参数数量和FLOPs在重复训练上的影响
- 6、小计算量模型的过拟合趋势与大计算量的差不多
- 7、多样的训练目标可以减轻多Epoch下降吗 MLM相对来说受影响会小一点
- 8、Dropout是一个被大语言模型忽视的正则技术,虽然慢,但是可以降低多epochs的影响
- 9、在训练过程中逐渐使用dropout是有效的策略
- 10、dropout对不同规模模型的影响不同 对大模型效果会更差一点
- 11、通过MoE扫描确定稠密模型的最佳超参数 由于MoE模型和稠密模型的训练趋势接近,因此可以先利用MoE的训练性能来进行提前的预估
- 多epochs训练对大语言模型性能影响的总结
SFT token
理论上只要较少的高质量token就能实现很好的效果。
当扩大数据量而不同时扩大提示多样性时,收益会大大减少,而在优化数据质量时,收益会大大增加。
特定任务的模型可能从固定的任务类型中获益,以获得更高的性能;指令格式的多样性可能对特定任务模型的性能影响很小;即使是少量的数据(1.9M tokens)也能为特定任务模型的指令调整带来可喜的结果。
不过具体可能倾向于任务,对于第一个结论,论文实际上只是对齐任务,因此。
对于第二个结论,可能需要一些手段提高token的质量,例如论文就是通过一些语言模型对文本进行embedding之后聚类采样才能在较小的数据中取得更好的效果。
Calculation of LLM
首先一个概念是:在给定计算量预算下,模型参数量以及训练Token数应该同比提升
| Parameters | FLOPs | FLOPs (in Gopher unit) | Tokens |
|---|---|---|---|
| 400 Million | 1.92e+19 | 1//29,968 | 8.0 Billion |
| 1 Billion | 1.21e+20 | 1//4,761 | 20.2 Billion |
| 10 Billion | 1.23e+22 | 1//46 | 205.1 Billion |
| 67 Billion | 5.76e+23 | 1 | 1.5 Trillion |
| 175 Billion | 3.85e+24 | 6.7 | 3.7 Trillion |
| 280 Billion | 9.90e+24 | 17.2 | 5.9 Trillion |
| 520 Billion | 3.43e+25 | 59.5 | 11.0 Trillion |
| 1 Trillion | 1.27e+26 | 221.3 | 21.2 Trillion |
| 10 Trillion | 1.30e+28 | 22515.9 | 216.2 Trillion |
不过考虑到自己的计算能力,一般不会选择太大的参数量。对于58M的NanoGPT,我们采用的token数量
预训练数据Token重复的影响:
- 多轮epoch的训练会降低模型性能;
- 更大规模的数据集会缓解重复epochs对模型性能下降的影响;
- 提高数据集的质量也无法挽救重复训练带来的过拟合;
- 小计算量模型的过拟合趋势与大计算量的差不多;
- 多样的训练目标不一定减轻多Epoch的性能下降;
- Dropout是一个被大语言模型忽视的正则技术,虽然慢,但是可以降低多epochs的影响;
- 在训练过程中逐渐使用dropout是有效的策略;
关于缩放定律,根据openai的论文,训练的损失和token数量,参数量具有如下函数关系:

DeepMind也做出了类似的研究,得出来的结论是模型参数量大小应该和token数量同比例增加。参考前面的表格。
接下来是详细的计算过程:
符号说明:
- n_layer:模型层数;
- d_model:模型残差输出维度大小;
- d_ff:前馈神经网络输出维度大小;
- d_attn:注意力网络输出维度大小;
- n_heads:每一层的多头注意力的数量;
- n_ctx:输入的上下文长度大小;
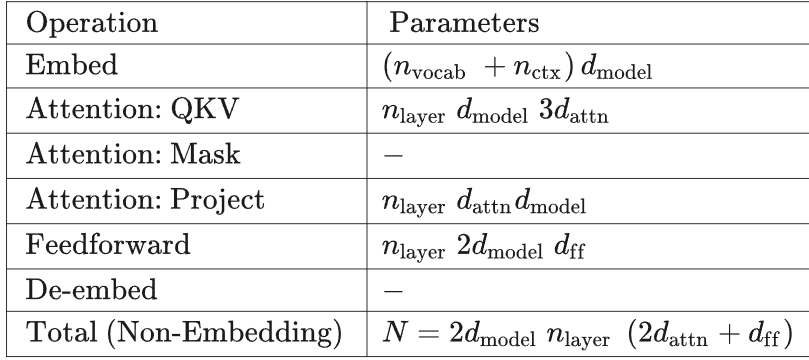
首先是参数量统计,embedding还是比较好计算的(注意,图标中的参数量指的是运算的时候的参数量,因此涉及到n_ctx的存储),QKV是三个矩阵,因此就是3*n_layer*d_model*d_attn。project是在完成attention操作时候的一个从attn维度到d的映射。feedforward一般来说是两个全连接层。因此整体的参数量就是最后的一个结果。

接下来是一个per token的FLOPS的计算。QKV的计算,很简单,就是在上述的基础上进行矩阵乘法+矩阵加法,由于是batch计算的,因此不会引入额外的FLOPS计算。同理应用于接下来的所有部分。最后的De-embed是一个矩阵乘法的过程,因此是2dn。至于embedding的FLOPS计算很奇怪。
要注意的是,SwiGLU会引入额外的参数量。在FFN的参数量计算过程中会把参数量变为原来的3/2倍。
激活值的计算
首先对于QKV,激活值为:
$$batch*n_{ctx}d_{model}$$
接着Mask:
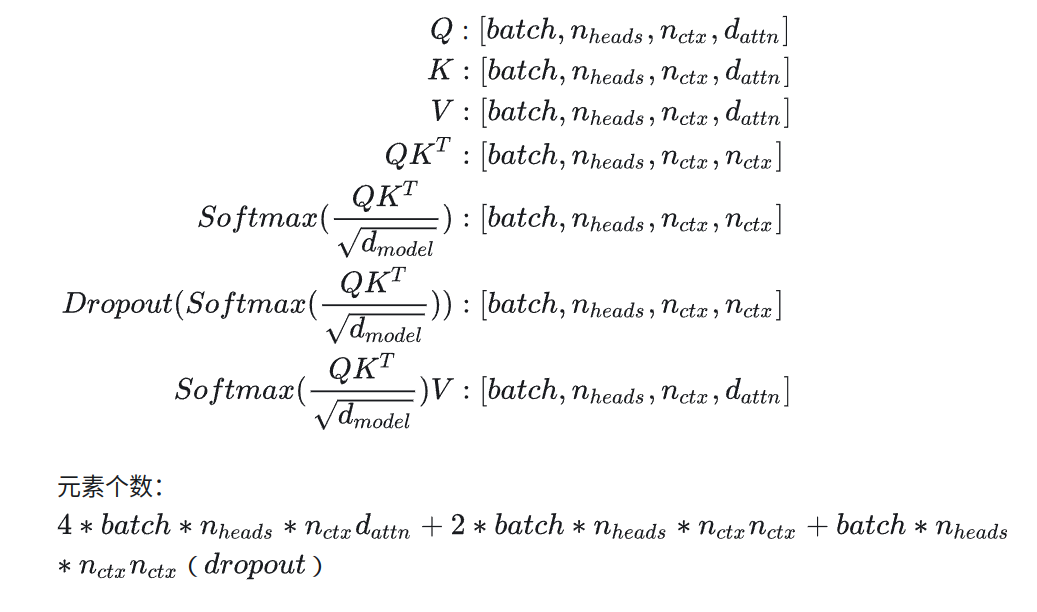



相当复杂的计算结构,但是接下来是可以化简的部分了。假设模型参数量为$\Phi$,当利用bfloat16的时候,参数存储为$2\Phi$。
在训练过程中的显存占用量主要包括:参数、梯度、优化器状态、中间激活值。假如利用bfloat16进行计算,则如下:

(注意,优化器采用double精度),但是中间激活值是与batch size相关的,因此增加batchsize会相当极端的提升显存占用。
训练时间估计:
对于每个token和模型参数,

(关于前向传播和反向传播的FLOP比例参考:https://epoch.ai/blog/backward-forward-FLOP-ratio:除了第一层以外,所有的层的backward:forward都是2:1)
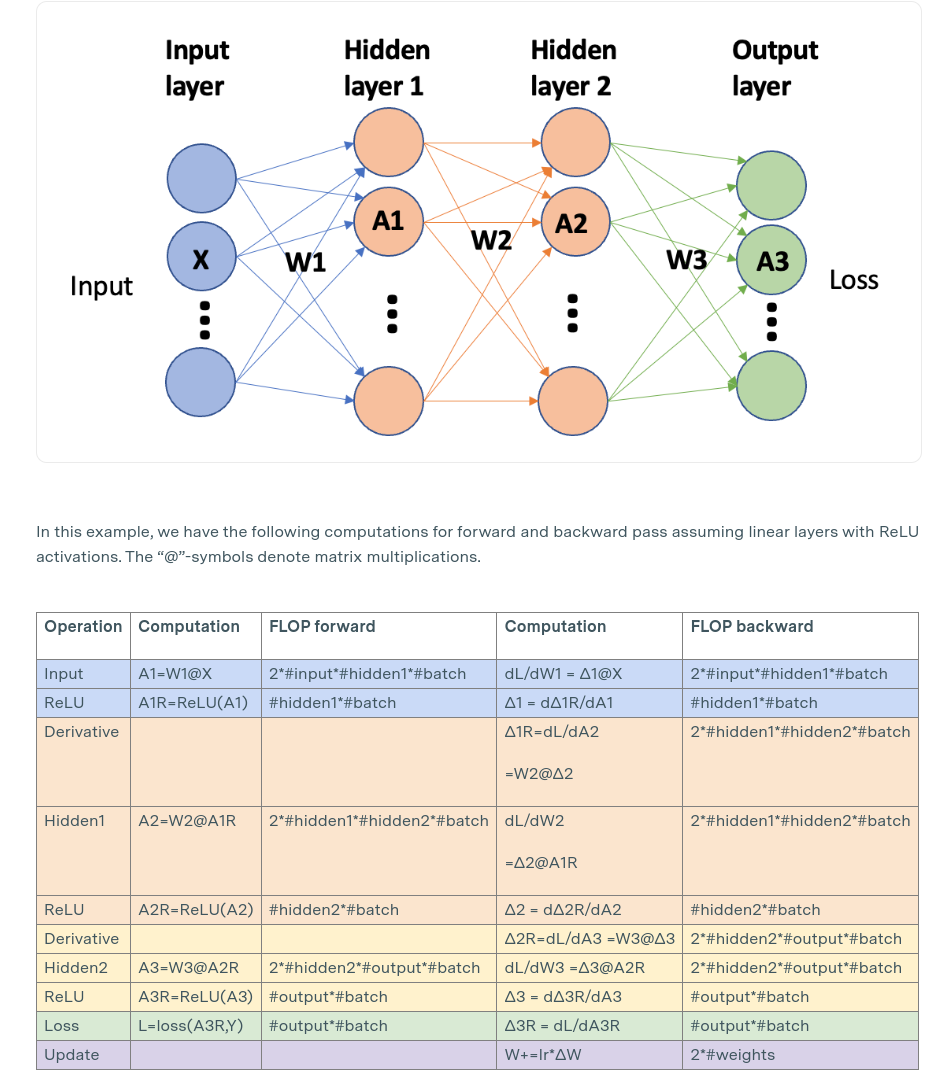
因此加上激活重计算的话FLOPS就基本正确了。此外由于参数计算需要进行两次浮点运算:乘法和加法,因而最后还X2了一下。当然,由于重计算不一定使用,因此实际的时间为:

DeepSeek Math
其实是一个很早期的DeepSeek的文章,来自于2024-04,但是这一波热潮使得全球都关注到了DeepSeek的相关工作。首先,核心来看的话其实工作量有两个
- 更大更多的数据
- GRPO策略
首先是数据问题,通过对数据域名评分并不断加入相关网站来不断扩充数据集的量,使得最终的数据量达到了120B,并在简单的测试中击败了诸多模型,证明数据集扩充的有效性。
其次是GRPO,相较于之前的RPO策略,论文生成了多个数据并采用KL散度进行计算从而达到更好的效果。其实从各个角度来看,都是对算力限制的一个近似。由于PPO需要将近4个语言模型来实现优化,因而为了减少算力需求,从而采用了这种方法。
大模型都做了什么
-
LLaMA1:预归一化、RMSNorm、SwiGLU 激活函数和旋转式位置编码
-
LLaMA2:扩展上下文长度到4096,采用GQA
-
LLaMA3:GQA+tik-token增加词汇量和训练数据
-
Qwen1:不知道
-
Qwen2:BPE字节对编码、GQA、双块注意力、SwiGLU、RoPE、pre-normalizaion、RMSNorm、MoE架构、DPO
-
Qwen3:牛而逼之、和前面的架构其实没啥变化,核心在与训练狠狠增加了很多科技,其中预训练先从无标注的数据开始训练,后面开始知识密集型训练最后是高质量长下文训练。后训练长思维链冷启动、推理RL、思维模式融合、通用强化学习
-
Deepseekv3:这个从推理性能以及推理价格上都有夸张的优化,做了负载均衡loss和MTP,还引入了MLA架构进一步降低kv-cache占用。除此之外还采用了FP8训练、Dualpipe等提高训练性能。