大模型推理加速
之前学了一些CUDA技巧,现在可以接触一下大模型推理加速技巧。
vLLM and PagedAttention
受操作系统中虚拟内存和分页的经典思想启发的注意力算法。

一段KV-cache会有很多浪费的空间,比如预留空间、内部碎片和外部碎片。此外。虽然batch-inference可以加快推理,但是如果遇到不能组成batch的情况时就会导致排队等待时间。(GEMM速度快于GEMV)
首先是内存问题,一个5120hidden_size的模型,长2048token的请求就会占用1.6GB左右的KV-cache,因此一个40G显存的设备一般只能容纳10条请求。尽管占用较多的内存,现在已经有一些方法尽可能的减少这种缓存了。但是论文的方法最终是为了解决内存中的碎片和不切实际的分配问题:
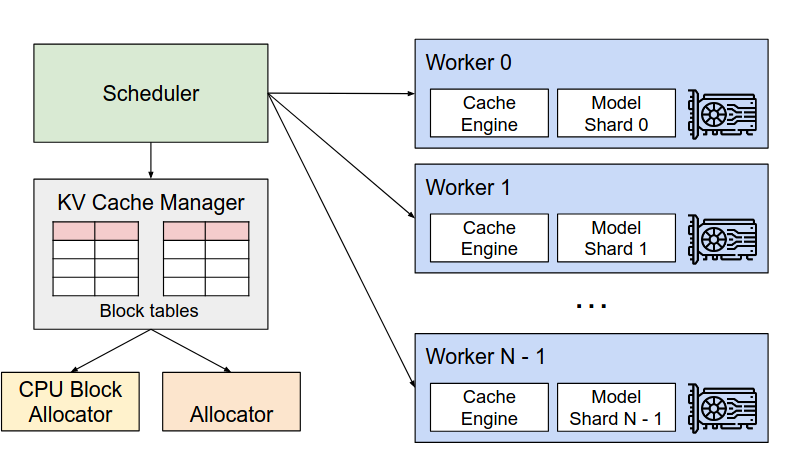
出图味来,确实像是页分配。
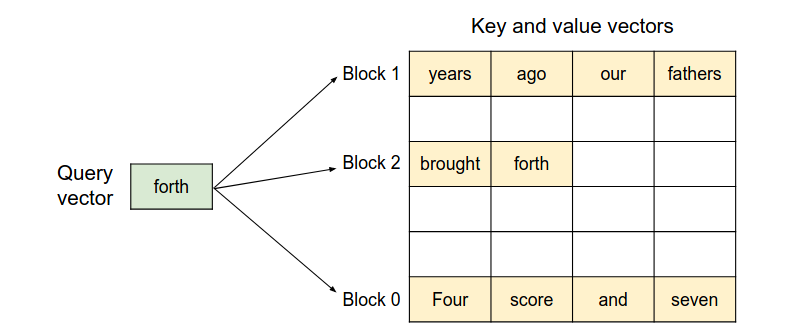
途中的已经被填充的方块就是前面第一个请求的语句,很容易可以看到不同块之间是不连续的。也就是说论文的算法支持KV-cache存储在不连续的空间中。
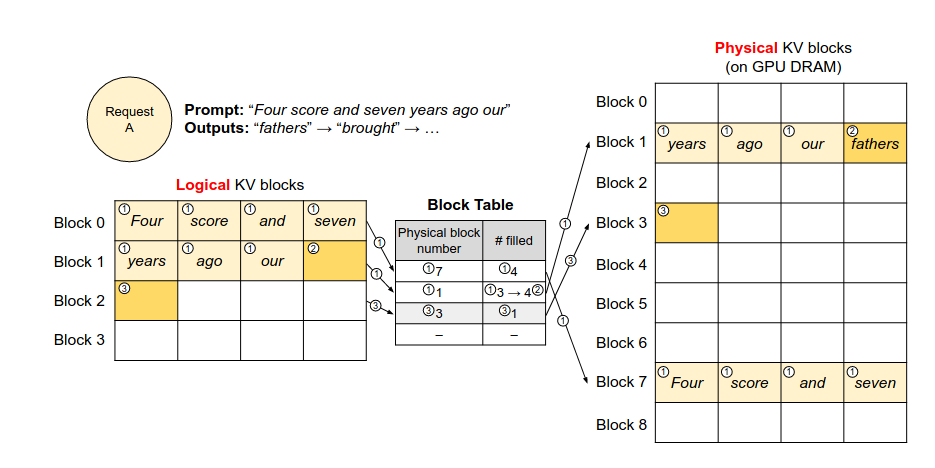
如图所示,生成第7个token时依次去除前面的内容,之后生成并填充到逻辑的Block1,如果满了则增加一张新项并填充到物理空间中。通过利用计数来实现并行的解码。对于Beam Search则采用对不同block的引用实现。
传统内存的一个问题就是交换空间的使用,这个同样会遇到该问题,在新的prompt到来时,由于存储问题,很容易出现OOM问题。因此和传统的内存管理问题一样,需要合理的交换和恢复。对于LLM推理,所有的块都是需要的,因此要不全部清出,要不全部获取。因此解决方案分别是swapping和recomputation。前者就是把暂时被抢占的放到CPU内存中,需要时重新取出。另一个手段就是直接从prompt开始重新计算。
除此之外论文还做了很多kernel上的操作来实现Transfomer运算和论文方法的融合,比如块级别的内存调度、attention和块读取的融合以及KV-cache位置的放置。
目前项目代码已经开源,考虑到其实用性,感觉还是有值得深究的必要的。
AWQ Activation-aware Weight Quantization for LLM Compression and Acceleration
一个量化手段,基于Activation进行权重的量化放缩而不是Weight,从而压缩和加速。
量化要尽可能减少量化误差,论文的一个思路在于GPT的权重重要度不同,有些权重重要性优于其他权重。歌女就这种思路,论文首先是对权重选择性的量化(根据L2范数),但是效果一般

但是其中基于Activation的量化效果显著,也就是这篇论文的核心。

首先是保护显著权重的方案,很简单,就是加了一个缩放s来减小精度损失。但是这个s不能过大也不能过小。一个较好的方法就是想办法训练一个scale参数出来:
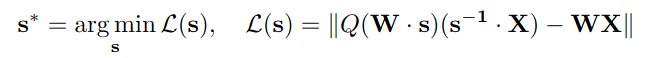
问题在于量化时候的这个过程是不可微的。所以加入一个参数$\alpha$在[0,1]每个频道网格搜索即可。
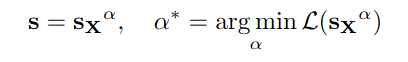
- 实现
- 基于python实现的
- 对每个module的参数网格化搜索scale
LITE Accelerating LLM Inference by Enabling Intermediate Layer Decoding
原理是Early-Exit
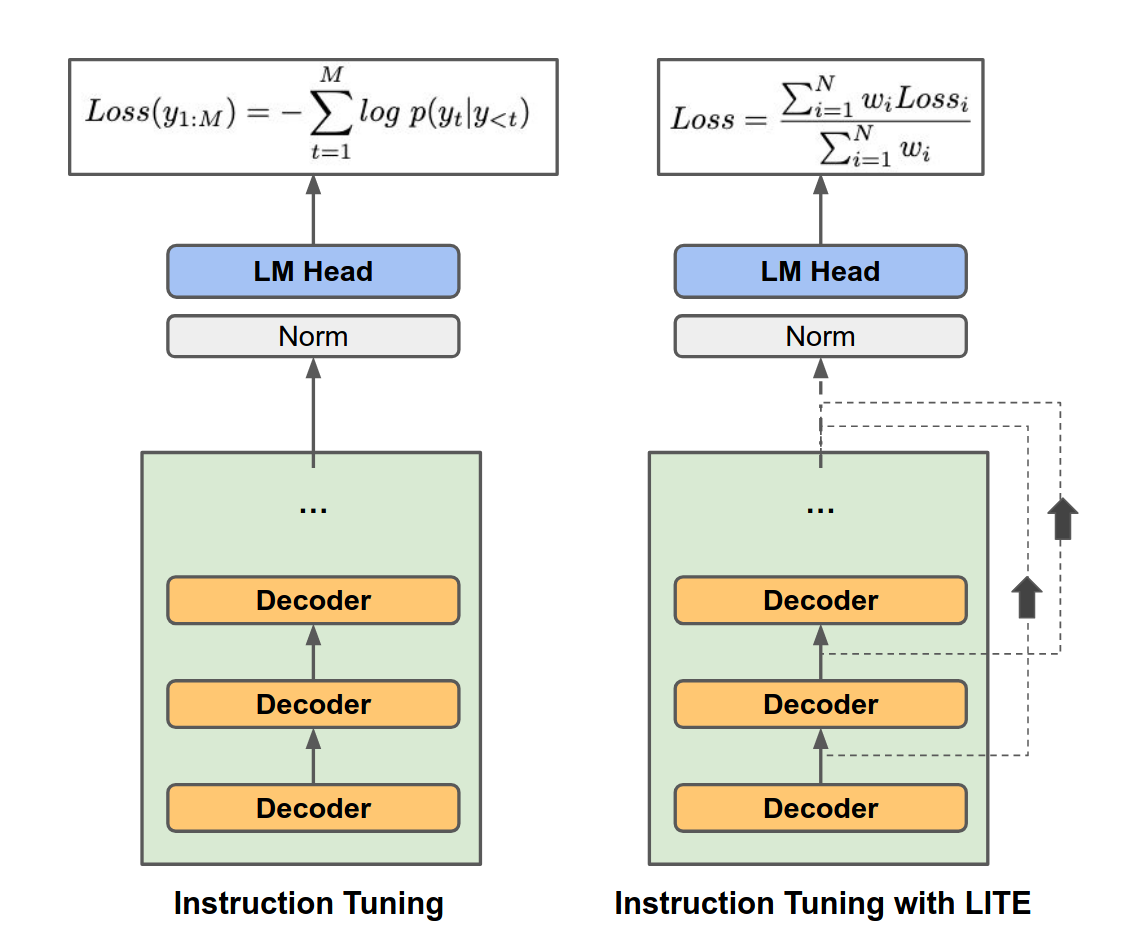
每一层都做一个LM-Head做退出。基于IT进行调整训练。最后用一个Threshhold进行判断是否EE