简单的mysql安装和一些配置目前不是重点,因为现在侧向工程向的使用,优先SQL语句的了解和使用。其中主要SQL语句主要以mysql为例,其次,将语句分为以下几部分:数据库的结构,涉及到数据库、表的创建和一些更改。另一部分则是数据处理,如增删改查和连接。后续还会涉及到一些mysql内置函数的学习,以及数据库的管理。
数据库的结构
库和表的创建
数据库是一个表的容器,所以创建一个数据库并没有什么难度,建表才是复杂的。建立一个数据库的指令如下:
CREATE DATABASE test
{CHARACTER SET latin1}
{COLLATE latin1_bin};
USE test;
DROP DATABASE test;
因为是首次接触SQL语句,所以要知道,SQL语句是以分号";“为分隔的。所以上述指令执行了三个命令:
- 创建一个名为test的数据库(之后也是一样,使用{}表示一些可添加的参数,在此创建的参数为字符集的设定和排序的规则)
- 设置test为默认的操作数据库
- 删除数据库test
不难看出,数据库的操作并不是很多,当然关键在于表的创建。对于一个表,我们创建时是需要设计它的列索引等属性(键、存储引擎这些)。为了方便理解,在写SQL语言时,我们通常会将每个列索引的属性定义写一行:
CREATE TABLE birds (
bird_id INT AUTO_INCREMENT PRIMARY KEY,
scientific_name VARCHAR(255) UNIQUE,
common_name VARCHAR(50),
family_id INT,
description TEXT);
上述语句创建了一张表birds,其中有5个索引,分别为:bird_id,scientific_name,common_name,family_id和description,其中每个索引值的属性也定义确定,如bird_id的数据类型就是整形。除此之外,我们还为bird_id添加了一些属性,如自动递增和主键,这些会在后续进行说明。创建完成的表可以通过DESCRIBE指令查看表属性:
DESCRIBE birds;

这些表的列索引分别表示:Field各列的标题,Type各列的类型,NULL各列能否含有NULL值,Key用于说明该列是否为索引列,Extra则表示一些额外的信息。
按道理在说明了数据库和表之后应该进一步,说明一下对记录(数据)的操作,但是这一章对库和表的内容尚未完全参透,所以将内容忍痛分开。原书中接下来的内容参考数据处理中的插入数据。
稍微深入一下表的创建
在了解了建库和建表的基本操作之后,显然,我们应该将目光放在表上。对于一个表,我们还可以通过如下语句进行属性的查看:
SHOW CREATE TABLE birds \G
即展示一张创建的表birds,后面的’\G’表示以非表格的形式将内容进行输出,输出结果如下:

相较于DESCRIBE,两者有显示内容的异同,其中最大的差距在于SHOW CREATE TABLE中可以结构化的看到表的主键和唯一键,以及存储引擎(这一点还是比较重要的)。这次不得不说明一下CHARSET和COLLATE的用途了,当表的建立不存在国际化的需求时,单一的字符集即可解决存储问题,但是在使用的过程中可能要涉及到产品应用范围的扩展,涉及到其他字符集的内容,这时候即可修改字符集来实现兼容,同时校对方式也要进行修改,以防止在排序时出现的问题。
除了上述表的属性以外,还应到深入的了解一下索引的属性(类型)。索引的数据类型有很多种,但严格来说可以归为三类:数值、日期/时间和字符串(字符)类型https://www.runoob.com/mysql/mysql-data-types.html。
除了新建表,复制表本质也是一种新建表,所以这里稍微提及一下复制表的方法:
CREATE TABLE new_table LIKE old_table;
INSERT INTO birds_new
SELECT * FROM old_table;
CREATE TABLE new_table
SELECT * FROM old_table;
上面展示了两种复制表的方法,两种的效果类似,虽然都涉及到了一个SELECT操作。对于前一种方法,首先使用CREATE…LIKE创建了结构相同的表,直至插入数据才将数据复制过去,第二种方法则是写到了一起。
更改表
这是十分合理的,毕竟我们不能保证创建的表是万无一失的,此外,在使用过程中也可能会进行表属性的修改,因此还是相当重要的。
在修改表之前,有个需要注意的点:建议备份,因为在更改过程中不免会出现一些操作失误导致数据的丢失,当然,这一点,关于数据备份的一些内容写在后面的数据备份章节。
正式的改表操作主要是ALTER操作。其简单语法如下:
ALTER TABLE table_name changes;
其中table_name为我要修改的表名称,changes为修改的具体命令,在实际的语句中,建议把changes和ALTER语句换行写,一会可以看到一些例子。为了使这个内容更像是一个小索引而不是一个面面俱到的书籍,所以我尽可能的将一些常用的ALTER操作放到了一起,供学习了解:
ALTER TABLE bird_family
ADD COLUMN order_id INT {AFTER family_id};
ALTER TABLE birds_new
ADD COLUMN body_id CHAR(2) AFTER wing_id,
ADD COLUMN bill_id CHAR(2) AFTER body_id,
ADD COLUMN endangered BIT DEFAULT b'1' AFTER bill_id,
CHANGE COLUMN common_name common_name VARCHAR(255);
ALTER TABLE bird_family
DROP COLUMN wing_id;
SHOW COLUMNS FROM birds_new LIKE 'endangered' \G
ALTER TABLE birds_new
MODIFY COLUMN endangered
ENUM('Extinct',
'Extinct in Wild',
'Threatened - Critically Endangered',
'Threatened - Endangered',
'Threatened - Vulnerable',
'Lower Risk - Conservation Dependent',
'Lower Risk - Near Threatened',
'Lower Risk - Least Concern')
AFTER family_id;
上面的指令表示了表列索引的添加,第一个是对表索引的单个添加,同时可以加入一些额外参数。第二个则是复杂的多列索引添加。第三条指令是对列的删除。对于索引,增删就是ADD和DROP,查就是DESCRIBE或者SHOW,对应的是上面的第四条指令,最后一条指令即为改索引,即:MODIFY COLUMN,最后一条指令将endangered列的数据类型改为枚举类型。除了改表,数据的更改使用UPDATE操作:
UPDATE table SET ;
其中table为要更新表名,SET为设置操作。
UPDATE birds_new SET endangered = 0
WHERE bird_id IN(1,2,4,5);
除了这些基础改表操作,还有一些比较特殊的,诸如修改默认值,设置自增,重命名和重排,修改默认值的命令如下:
ALTER TABLE birds_new
CHANGE COLUMN endangered conservation_status_id INT DEFAULT 8;
ALTER TABLE birds_new
ALTER conservation_status_id DROP DEFAULT;
上面的两条指令进行了表的默认值修改。第一条指令首先进行了列索引的改名,之后设置默认值为8。第二条指令展示了删除默认值的指令。设置自增的命令如下:
ALTER TABLE birds
AUTO_INCREMENT = 10;
不常见,但是得知道有这种用法。重命名一个表的操作很简单:
RENAME TABLE old_name TO new_name;
RENAME TABLE rookery.birds TO rookery.birds_old,
test.birds_new TO rookery.birds;
第一条命令即将表由old_name修改为new_name。第二条命令有点类似linux系统下的cp指令,即在同一目录cp只是单纯的修改文件名,这里的操作将rookery库中的表birds改名为birds_old,同时将test中的表birds转移到了rookery下,并改名为了birds。表的重排序往往和SELECT配合使用,示例如下:
ALTER TABLE country_codes
ORDER BY country_code;
SELECT * FROM country_codes
ORDER BY country_name
LIMIT 3;
上述的两个指令,第一个将表以country_code作为依据重排序,第二条指令从表中提取所有记录,并以country_name为依据重排,显示前三条。
索引对于表的整体处理是比较重要的,尤其是未来涉及到链接的相关操作,索引的相关操作如下:
SHOW INDEX FROM humans \G
ALTER TABLE birdwatchers.humans
ADD INDEX human_names (name_last, name_first);
SHOW INDEX FROM birdwatchers.humans
WHERE Key_name = 'human_names' \G;
ALTER TABLE conservation_status
DROP PRIMARY KEY,
CHANGE status_id conservation_status_id INT PRIMARY KEY AUTO_INCREMENT;
上面展示了四条SQL的索引操作指令,第一条即为简单的展示一个表的索引。第二条为创建了一个索引。第三条是对索引值的查询。第四条可能才是实际使用中用的最多的,删掉主键,将status_id改名为conservation_status_id并重新设置为主键。
数据处理
在了解了库和表级别的操作之后,实际上,使用最频繁的还是增删改查已有的数据库,接下来将会学习一些增删改查的操作。
数据插入
数据的插入有多种方式,其中一种方式如下:
INSERT INTO table [(column, ...)]
VALUES (value, ...), (...), ...;
使用INSERT INTO向表中添加内容,其中table为表名,方括号为可选的列索引集合,这与下面VALUES中的内容是一一对应的,当忽略方括号中的内容时,下面需要导入一个记录中的所有列所以,示例如下:
INSERT INTO books
VALUES('The Thirty-Nine Steps', 'John Buchan', DEFAULT);
INSERT INTO books
(author, title)
VALUES('Evelyn Waugh','Brideshead Revisited');
上面是两种示例,具有一定的代表意义,第一个是向所有的列索引中添加内容,并与索引一一对应,其中第三个列索引的值使用定义时的默认值。第二个则是只对列索引中的author,title两个索引添加内容。
除了上述简单的插入,还有下面的几种插入方法:
INSERT INTO bird_families
SET scientific_name = 'Rallidae',
order_id = 113;
INSERT IGNORE INTO bird_families
(scientific_name, brief_description, cornell_bird_order)
SELECT bird_family, examples, bird_order
FROM cornell_birds_families_orders;
第一种插入方法叫做明确插入,十分显然,其就是将每个键设定对应的值然后执行。第二种方法则是从其他表中迁移数据,有点类似linux系统下的管道操作,可以理解为将SELECT查询得到的结果导入表中。此外,上面有一个没有见过的参数:IGNORE,这指的是忽略复制过程中的错误。
替换数据也可以是看作数据插入,示例如下:
REPLACE INTO bird_families
(scientific_name, brief_description, order_id)
VALUES('Viduidae', 'Indigobirds & Whydahs', 128),
('Estrildidae', 'Waxbills, Weaver Finches, & Allies', 128),
('Ploceidae', 'Weavers, Malimbe, & Bishops', 128);
因为INSERT在遇到重复值时会产生报错(所以使用IGNORE),而REPLACE可以有效避免这个问题,因为它可以将出现重复的键进行替换。
查询语句
查询语句在之前的内容中或多或少都已经涉及到了,其核心为:
SELECT columns FROM table
{WHERE condition};
上述的语句即可实现简单的语句查询,大括号中的内容为可以加入的条件查询。实际操作并没有什么难度,其中的条件语句可以使用编程语言中的逻辑表达式,但是这只不过是简单的条件语句,还有一种语句是以LIKE作为条件语句的,如下:
SELECT common_name AS 'Bird',
families.scientific_name AS 'Family',
orders.scientific_name AS 'Order'
FROM birds, bird_families AS families, bird_orders AS orders
WHERE birds.family_id = families.family_id
AND families.order_id = orders.order_id
AND common_name LIKE 'Least%'
ORDER BY orders.scientific_name, families.scientific_name, common_name
LIMIT 10;
这个查询可以说非常复杂了,包含了查询语句的很多操作,该语句选择了三个表中的三列数据并使用了三个条件语句限定记录,而其中的第三个条件语句即为我们的LIKE条件表达,其将获取common_name中所有带有"Least"的内容的记录。

LIKE操作是用于做模式匹配的,除了LIKE以外,还可以使用REGEXP:
SELECT common_name AS 'Hawks'
FROM birds
WHERE common_name REGEXP BINARY 'Hawk'
AND common_name NOT REGEXP 'Hawk-Owl'
ORDER BY family_id LIMIT 10;
REGEXP和LIKE有点类似,只不过它支持更多的模式匹配。在上面的例子,最终会查到表中名字带有"Hawk"的记录。有一点要注意的是,REGEXP后添加了BINARY,这意味着以二进制的形式来进行查找"Hawk"关键字(因为H和h的二进制值是不同的),结果只包含了"Hawk"的,而不包含其它带有上面字母的单词。实际上,使用REGEXP进行匹配时,结果与表创建时COLLATE值有关。因为birds表的COLLATE值为"latin1_bin"即Latin1二进制,所以即使不加BINARY,在匹配时也只能匹配到"Hawk”
上面的复杂语句包含了很多操作如排序、限定,下面看一个简单的例子:
SELECT common_name, scientific_name, family_id
FROM birds
WHERE family_id IN(103, 160, 162, 164)
AND common_name != ''
ORDER BY common_name
LIMIT 3, 2;
上面的指令就是一个综合的语句,其包含了条件查询、限定结果和排序。其中排序为其中的ORDER BY column实现,限定结果为LIMIT,后面的两个数指的是从第三行之后开始显示两行,即显示结果中的3、4行。
在查表的过程中,我们偶尔会需要同时查询多个表,一个示例如下:
SELECT common_name AS 'Bird',
bird_families.scientific_name AS 'Family'
FROM birds, bird_families
{WHERE birds.family_id = bird_families.family_id
AND order_id = 102
AND common_name != ''
ORDER BY common_name LIMIT 10;}
上面的命令显示了两张表中的两列索引,其发挥查找两个表的地方在于SELECT 中制定了两个表和两个列(也使用了别名),大括号中的内容即为其余的一些东西。
更新数据
数据库中的数据经常发生变化,可能包含信息的添加或是记录的删除。信息的添加我们使用UPDATAE语句实现而删除记录使用DELETE。上面短短的两句话有两个要点,一是表信息的添加时UPDATE而不是记录的添加,另一点是记录的删除不是DROP
首先是数据的更新:
UPDATE table
SET column = value, ... ;
有点类似INSERT指令,都需要添加SET,但是UPDATE没有INTO,而表名是紧跟UPDATE语句的。所以康康下面的这个例子:
UPDATE humans
SET formal_title = 'Ms.'
WHERE formal_title IN('Miss','Mrs.');
更新humans表,其中吧规范标题为Ms.的修改为Miss和Mrs.。
更新的另一个操作时更新多个表
UPDATE prize_winners, humans
SET winner_date = NULL,
prize_chosen = NULL,
prize_sent = NULL
WHERE country_id = 'uk'
AND prize_winners.human_id = humans.human_id;
不难看出,需要进行多个表的更新时,只需要将UPDATE后的关键字设置为多个表即可,将其中来自英国的且中奖过的人的数据据给刷新一遍。
UPDATE prize_winners, humans
SET winner_date = CURDATE()
WHERE winner_date IS NULL
AND country_id = 'uk'
AND prize_winners.human_id = humans.human_id
ORDER BY RAND()
LIMIT 2;
接下来我们只需要执行上述语句就可以得到没有获奖且为英国人进行抽奖,但是实际上,上述语句是会报错的因为多表的更新是不能使用LIMIT或是ORDER BY的(因为更新多个表的返回值为多个表,无法确定究竟哪个表需要进行排序),应当使用子查询的方式进行,具体的内容将会在后面见到。
处理重复值时往往也会用到UPDATE语句,为什么没有放在INSERT中进行说明,这是因为处理重复可以配合UPDATE指令实现一些功能:
INSERT INTO humans
(formal_title, name_first, name_last, email_address, better_birders_site)
VALUES('Mr','Barry','Pilson', 'barry@gomail.com', 1),
('Ms','Lexi','Hollar', 'alexandra@mysqlresources.com', 1),
('Mr','Ricky','Adams', 'ricky@gomail.com', 1)
ON DUPLICATE KEY
UPDATE better_birders_site = 2;
上面的语句就是向humans表中插入一些数据,遇到重复的键时将bbs的值设置为2,从而实现了重复键的处理。这里整一个子查询语句来稍微了解一下:
INSERT INTO possible_duplicates
SELECT name_first, name_last
FROM
(SELECT name_first, name_last, COUNT(*) AS nbr_entries
FROM humans
GROUP BY name_first, name_last) AS derived_table
WHERE nbr_entries > 1;
先看圆括号里的内容,从humans统计出每个名字和该名字的计数,并将计数命名为nbr_entries,之后我们对这个子表进行一个INSERT处理,从中获取nbr_entries(重复)大于2的数据并进行数据的插入。
删除数据
删除数据自然重要,但是在继续了解其具体的语句之前,我们就可以想到DELETE语句应该怎么用了,DELETE后可以加条件或组,从而实现条件的删除,并限定一些数量,所以记录删除的基本语句如下:
DELETE FROM table
[WHERE condition]
[ORDER BY column]
[LIMIT row_count];
DELETE FROM table[, table]
USING table[, . . . ]
[WHERE condition];
上面的语句中,前一个是单表的删除,而后一个是多表的删除,删除单表的操作并非十分困难,要搞还是得搞点多表的删除,一个例子如下:
DELETE FROM humans, prize_winners
USING humans JOIN prize_winners
WHERE name_first = 'Elena'
AND name_last = 'Bokova'
AND email_address LIKE '%yahoo.com'
AND humans.human_id = prize_winners.human_id;
多表的删除要考虑到表与表之间的外键连接,如上面的实例,使用using将列出两表并声明他们的连接关系。之后根据条件语句进行一个表内容的删除。
上面仅仅列举了DELETE操作的一部分内容,当然,实际上这些操作也足够我们进行一些基础的使用了,复杂的操作仍然需要进行更深一步的学习,限于篇幅而不在此列举。
表连接
如果说之前的内容只是对单表的一些处理和查询,那么表连接的内容就是对表进行一些关系上一些处理。
首先要了解的操作是一个物理的联结UNION操作,很容易,例子如下:
SELECT 'Pelecanidae' AS 'Family', COUNT(*) AS 'Species'
FROM birds, bird_families AS families
WHERE birds.family_id = families.family_id
AND families.scientific_name = 'Pelecanidae'
UNION
SELECT 'Ardeidae', COUNT(*)
FROM birds, bird_families AS families
WHERE birds.family_id = families.
family_id
AND families.scientific_name = 'Ardeidae';
简而言之就是将两张表的内容联结输出,结果如下:

对于表一,首先是进行了一个别名的操作,之后将表bid_families也进行了别名,将其中家庭id和科学名称为P的列举出来,第二个同理。要注意的是,结果表的标题是从第一个SELECT语句中获取的,再者,结果得到的Family的内容中都是我们别名得到的。
UNION只能和SELECT中使用。对于合并后的表,可以使用ORDER BY进行排序。UNION在进行多表的合并显示时确实具有很好的效果,但是可能比较冗杂。
那么接下来就是正统的表连接内容了,首先是比较基础的表连接查询:
SELECT common_name, conservation_state
FROM birds
JOIN conservation_status
USING(conservation_status_id)
WHERE conservation_category = 'Threatened'
AND common_name LIKE '%Goose%';
从birds表中搜索cname和cstate两列,之后加入一个新表——c_status表,使用其c_status_id(因为这的c_status表的c_status_id索引和birds表的c_state共享数据)。

再来一个更加复杂的:
SELECT common_name AS 'Bird',
bird_families.scientific_name AS 'Family', conservation_state AS 'Status'
FROM birds
JOIN conservation_status USING(conservation_status_id)
JOIN bird_families USING(family_id)
WHERE conservation_category = 'Threatened'
AND common_name REGEXP 'Goose|Duck'
ORDER BY Status, Bird;
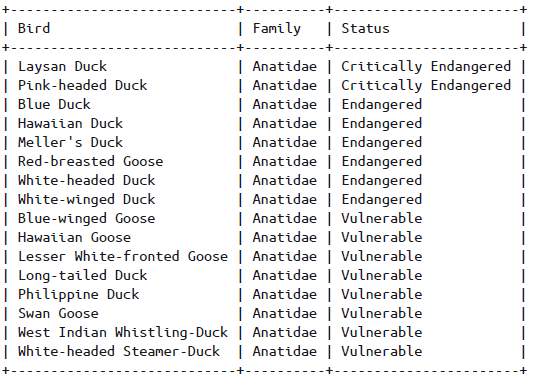
这次加入了两个表,到这里,看到SQL语句就可以基本理解了,我们显示表Birds的内容,但是引入了其余表的条件,从而显示出了在其余表条件下改表满足条件的记录。
JOIN的还有其他写法来实现各种各样的连接,其中一个操作是LEFT JOIN,左连接,例子如下:
SELECT common_name AS 'Bird',
conservation_state AS 'Status'
FROM birds
LEFT JOIN conservation_status USING(conservation_status_id)
WHERE common_name LIKE '%Egret%'
ORDER BY Status, Bird;
该操作会查出左表中满足条件的行,而不管在右表中的行。
那么不仅仅是查询操作可以使用这个操作,数据的更新和删除同样也可以使用上述操作:
UPDATE birds
LEFT JOIN conservation_status USING(conservation_status_id)
JOIN bird_families USING(family_id)
SET birds.conservation_status_id = 9
WHERE bird_families.scientific_name = 'Ardeidae'
AND conservation_status.conservation_status_id IS NULL;
上述例子中,连接了3个表,并将bird_family中的科学名为A的鸟且现存状态未知的鸟记录从birds表中将现存状态修改为9。
这里的一个好建议是:因为SELECT语句和UPDATE语句是相同的,所以在进行UPDATE操作之前,可以使用SELECT语句首先查看一下是否满足自己预期的结果。
删除的一个例子如下:
DELETE FROM humans, prize_winners
USING humans JOIN prize_winners
WHERE name_first = 'Elena'
AND name_last = 'Bokova'
AND email_address LIKE '%yahoo.com'
AND humans.human_id = prize_winners.human_id;
不知道有没有发现猫腻,在DELETE中的USING JOIN语句与其他情况下是不完全相同的。上述语句实现了从humans表和prize_winners表中删除满足条件一个人信息的操作。在删除时,USING和JOIN后都需要指定表名,这是因为删除的限制条件并不多,实际上,我们只需要在这两个表中找到满足条件的记录,并把行删除即可。
与前面的JOIN用法类似,删除时也有LEFT JOIN操作,当同时满足了左右表的条件时,才会进行删除,而LEFT JOIN则可以在只满足左表条件的情况下就删除左表的内容。同理,RIGHT JOIN可以实现相反的操作。
子查询
子查询是指一个查询被包含在另一个查询中,虽然看上去很没用:我们只需要充分使用连接和条件就可以实现各种查询,但子查询的好处在于模块化查找操作,从而更方便调试和组织。不过要注意的是,子查询并不能说是特殊语法,只是SQL的一种语句组织方式。
康康下面两个例子:
UPDATE table_1
SET col_5 = 1
WHERE col_id =
SELECT col_id
FROM table_2
WHERE col_1 = value;
SELECT column_a, column_1
FROM table_1
JOIN
(SELECT column_1, column_2
FROM table_2
WHERE column_2 = value) AS derived_table
USING(col_id);
上面的第一个例子,首先使用SELECT进行内部查询,之后使用UPDATE进行外部查询,第二个类似。但是有个限制是外部查询一般不能修改内部查询所查的表。我们先不尝试解释上面的语句,先看看子查询的几个类型:标量子查询、列子查询、行子查询和表子查询。
标量子查询就是返回单个值,和WHERE搭配起来有奇效:
SELECT scientific_name AS Family
FROM bird_families
WHERE order_id =
(SELECT order_id
FROM bird_orders
WHERE scientific_name = 'Galliformes');
上面的语句中,子查询语句从bird_order表的secientific为’Galliformes’记录的order_id进行获取,之后外查询获得了这一标量并返回查询结果。
列子查询的例子如下:
SELECT * FROM
(SELECT common_name AS 'Bird',
families.scientific_name AS 'Family'
FROM birds
JOIN bird_families AS families USING(family_id)
JOIN bird_orders AS orders USING(order_id)
WHERE common_name != ''
AND families.scientific_name IN
(SELECT DISTINCT families.scientific_name AS 'Family'
FROM bird_families AS families
JOIN bird_orders AS orders USING(order_id)
WHERE orders.scientific_name = 'Galliformes'
ORDER BY Family)
ORDER BY RAND()) AS derived_1
GROUP BY (Family);
又臭又长,但是一点点看吧。这语句有两个子查询(嵌套子查询),从内向外吧(这跟python的数据分析有的一拼了)。最深层的查询进行了进行了连接操作,将表bird_families和bird_orders进行了连接,并把其中满足条件的记录以Family为关键字进行排序并返回唯一记录的scientific_name信息,也就是说,该子查询进行了一个学名的返回。接下来的上一层查询,以该学名列表为其中一个条件,同时连接了几个表,返回一个birds中的两列并随机排序,最外层的查询将提取出来的内容进行分组。从而得到了如下效果

当然,可以看出来最外层的查询和第一层子查询完全是可以何为一个的。
行子查询的例子更是重量级:
INSERT INTO bird_sightings
(bird_id, human_id, time_seen, location_gps)
VALUES
(SELECT birds.bird_id, humans.human_id,
date_spotted, gps_coordinates
FROM
(SELECT personal_name, family_name, science_name, date_spotted,
CONCAT(latitude, '; ', longitude) AS gps_coordinates
FROM eastern_birders
JOIN eastern_birders_spottings USING(birder_id)
WHERE
(personal_name, family_name,
science_name, CONCAT(latitude, '; ', longitude) )
NOT IN
(SELECT name_first, name_last, scientific_name, location_gps
FROM humans
JOIN bird_sightings USING(human_id)
JOIN rookery.birds USING(bird_id) ) ) AS derived_1
JOIN humans
ON(personal_name = name_first
AND family_name = name_last)
JOIN rookery.birds
ON(scientific_name = science_name) );